Gemma-4 sur le DGX Spark : le prix du contexte
Neuf benchmarks de Gemma-4-26B-A4B-it sur le DGX Spark avec llama-benchy et vLLM. Le decode tient ; le prefill et la file d'attente decident du ressenti.
Je voulais savoir comment un DGX Spark se comporte comme machine d’IA locale pour un environnement de bureau.
Pas en théorie. Juste : charger Gemma-4-26B-A4B-it dans vLLM, lui balancer llama-benchy, agrandir les context windows, allonger l’output, monter la concurrency, ajouter du multi-turn, et regarder où ça reste agréable et où l’attente commence à faire mal. Et quand cette histoire a commencé à se dessiner, une deuxième question est arrivée : et si je n’effectue plus mes tests en lockstep, mais que je laisse les requêtes arriver de façon organique, comme dans un vrai bureau ? Pour ça j’ai pris la suite de benchmark de vLLM elle-même, qui fait ce que llama-benchy ne fait pas : arrivées de Poisson, percentiles, vraies données de conversation. Comment je mesure tout ça, c’est dans la methodologie.
La version courte : pour un usage de bureau normal, ça a l’air bon. Des prompts courts à moyens, des outputs plus longs, et même des conversations sur plusieurs tours restent rapides au ressenti, même avec dix utilisateurs en même temps. Avec de grands context windows, le problème n’est pas les tokens par seconde, mais combien de temps quelqu’un fixe une fenêtre de chat vide avant que le premier token n’arrive. Et si tu surcharges vraiment la machine, elle ne scale pas, elle met en file.
Ça n’en fait pas une histoire de “le DGX Spark y arrive ou pas”. Ça en fait une histoire de workload. Neuf tests, deux méthodes, une machine. C’est l’un des build logs sous le guide faire tourner des LLMs sur le DGX Spark.
Pourquoi ce test
Avec l’IA on-prem, tu en viens vite à parler de vie privée, de garder les données plus près et d’être moins dépendant de modèles hébergés. Tout ça est vrai, mais finalement une question plus plate suit.
La machine peut-elle encaisser ?
Un modèle local qui répond proprement à un seul prompt de démo, c’est sympa. Mais la production ressemble rarement à ça. Là tu as plusieurs utilisateurs, un contexte plus grand, des agent flows, des tool-calls, des retries et parfois quelqu’un qui colle un demi-roman dans un ticket.
C’est pourquoi je ne voulais pas mesurer uniquement les tokens par seconde sur un seul prompt. Je voulais voir ce qui se passe quand on charge la machine sous différents angles : de “dix utilisateurs, prompts courts, longues réponses” à “dix utilisateurs, conversations de cinq tours, mémoire croissante” jusqu’à “des requêtes qui arrivent de façon organique comme dans un vrai bureau, pas toutes en même temps et pas toutes du même format”.
Pour ces benchmarks j’ai testé un seul modèle :
google/gemma-4-26B-A4B-it- BF16
- DGX Spark, NVIDIA GB10, 128 GB unified memory
- vLLM comme endpoint compatible OpenAI
Le dense viendra plus tard. MoE vs dense aussi. Cet article ne parle que de Gemma-4-26B-A4B-it sur le DGX Spark. Ce run tourne en BF16 ; ce qui arrive au même Gemma-4 quand tu quantises en NVFP4 est une autre histoire.
Ce que j’attendais au départ
Mon attente était simple : le MoE resterait raisonnablement bon sous requêtes concurrentes, mais je pensais que le DGX Spark atteindrait ses limites plus vite dès que le contexte deviendrait grand.
Surtout à 25k de contexte.
Le contexte coûte cher. Tu payes non seulement le prompt qui entre, mais aussi le KV-cache que vLLM doit tenir à jour. Multiplie ça par plusieurs utilisateurs et ça devient d’un coup un problème de mémoire et un problème de file d’attente.
J’étais curieux de cinq choses :
- le decode reste-t-il utilisable quand le contexte grandit ?
- combien le prefill ajoute-t-il au temps jusqu’au premier token ?
- que se passe-t-il quand le prompt est court mais l’output long ?
- comment se comporte-t-il avec des conversations multi-turn, où le contexte s’épaissit à chaque tour ?
- et (ajouté seulement plus tard) à quoi ressemble tout ça quand les requêtes n’arrivent pas en lockstep, mais de façon organique ?
Cette dernière question s’est révélée être la moitié de l’histoire.
L’installation de test
Le serveur tournait dans Docker avec l’image officielle de vLLM :
docker run -d --name vllm-bench \
--gpus all --ipc=host \
-v appliance_hf-cache:/root/.cache/huggingface \
-p 8000:8000 \
vllm/vllm-openai:v0.20.1 \
--model google/gemma-4-26B-A4B-it \
--served-model-name gemma-4-26b-a4b-bf16 \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--kv-cache-dtype fp8 \
--limit-mm-per-prompt '{"image":0,"audio":0}' \
--async-scheduling \
--no-enable-prefix-caching \
--host 0.0.0.0 \
--port 8000Quelques détails comptent.
Le prefix caching est volontairement coupé. Je voulais d’abord voir le coût brut du prefill, pas un benchmark qui s’embellit parce que les prompts se ressemblent.
Le KV-cache tourne en fp8. Sans ça, 128k de contexte avec plusieurs requêtes en même temps devient vite un exercice de mémoire dont tu ne tires pas grand-chose.
Les neuf tests ci-dessous utilisent exactement cette config serveur. Pas de redémarrage, pas d’ajustement en cours de route. Ce qui varie, c’est le workload : taille du prompt, taille de l’output, concurrency, depth, et pour les tests open-loop aussi l’arrival rate et la burstiness.
Ce que le Spark en fait :
| Composant | Valeur |
|---|---|
| Model weights (BF16) | ~48 GB |
| KV-cache headroom (fp8) | ~65 GB |
| Parallele theorique @ 128k | ~4 requests |
| Parallele theorique @ 8k | ~50 requests |
À plein contexte par requête, la mémoire est juste. En pratique aucun test n’utilise 128k en même temps par utilisateur, donc le goulot se déplace vers le prefill-compute et le scheduler-batching. On le retrouve ci-dessous.
Run A : agrandir le contexte
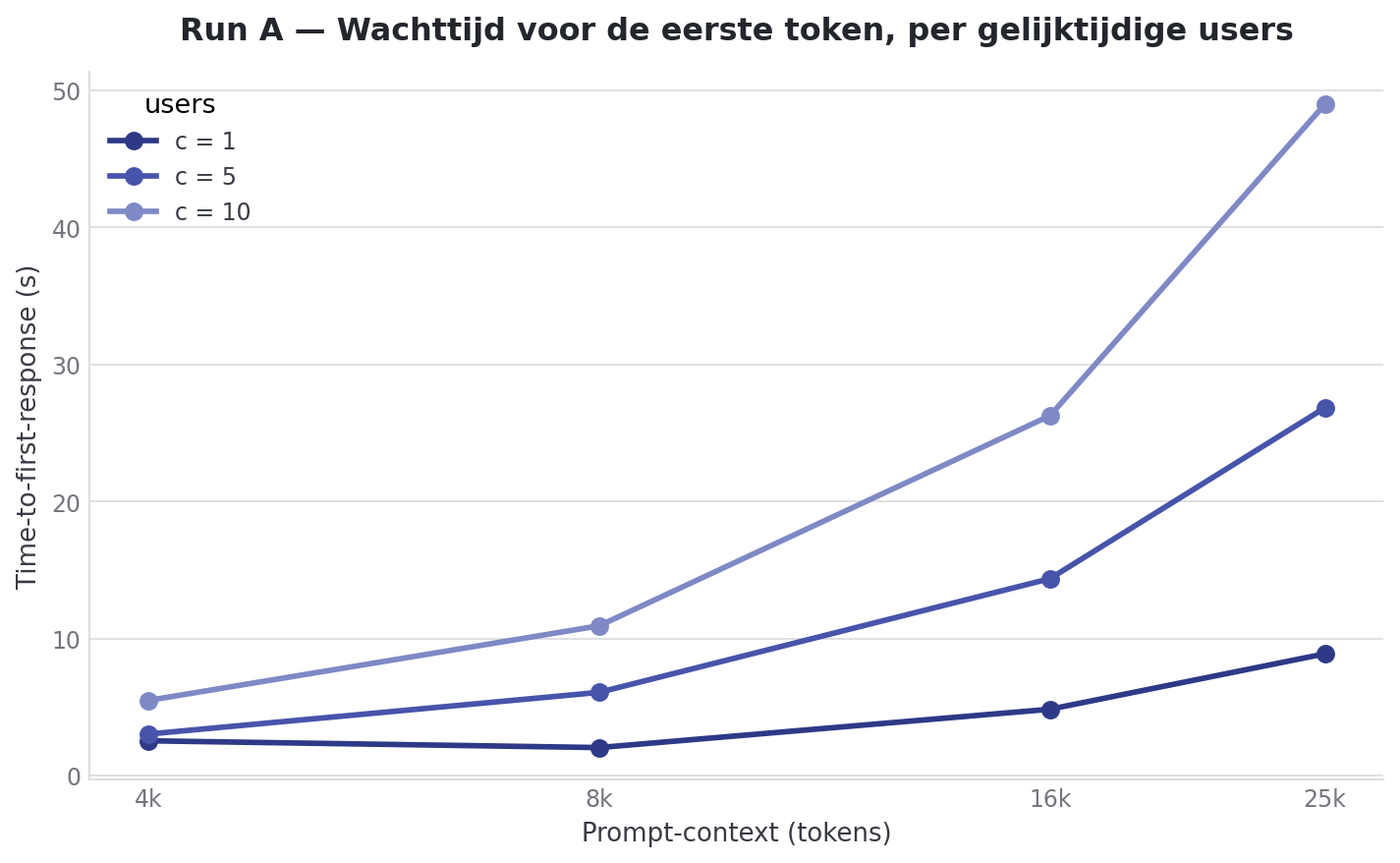
Le premier run faisait grandir le contexte de 4k à 25k. La concurrency suivait de 1 à 5 et 10. Closed-loop, donc N utilisateurs en lockstep.
uvx llama-benchy \
--base-url http://localhost:8000/v1 \
--model gemma-4-26b-a4b-bf16 \
--pp 4096 8192 16384 25000 \
--tg 256 \
--depth 0 \
--concurrency 1 5 10 \
--runs 3 \
--latency-mode generation \
--format mdpp c’est le prefill, c’est-à-dire combien de prompt tokens entrent. tg c’est le decode, c’est-à-dire combien de tokens le modèle génère ensuite. llama-benchy rapporte mean ± stddev. Pas de p95. C’est important à retenir, car sur la latence tu te racontes sinon vite des histoires.
Voici le résumé du Run A :
| Contexte | Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|---|
| 4k | 1 | 3677.85 ± 1259.27 tok/s | 24.08 ± 0.02 tok/s | 24.08 ± 0.02 tok/s | 1.37 ± 0.52s |
| 4k | 5 | 5722.96 ± 94.70 tok/s | 12.55 ± 0.49 tok/s | 57.07 ± 2.64 tok/s | 2.29 ± 0.82s |
| 4k | 10 | 5475.53 ± 888.14 tok/s | 9.48 ± 0.73 tok/s | 84.40 ± 3.08 tok/s | 4.46 ± 2.38s |
| 8k | 1 | 6121.87 ± 62.31 tok/s | 23.69 ± 0.02 tok/s | 23.69 ± 0.02 tok/s | 1.39 ± 0.01s |
| 8k | 5 | 5444.57 ± 12.82 tok/s | 11.48 ± 0.92 tok/s | 49.42 ± 1.60 tok/s | 4.34 ± 1.91s |
| 8k | 10 | 5478.98 ± 11.48 tok/s | 8.52 ± 1.10 tok/s | 67.72 ± 0.91 tok/s | 7.99 ± 4.03s |
| 16k | 1 | 4607.64 ± 23.05 tok/s | 23.34 ± 0.05 tok/s | 23.34 ± 0.05 tok/s | 3.42 ± 0.00s |
| 16k | 5 | 4466.35 ± 27.19 tok/s | 10.05 ± 1.75 tok/s | 38.41 ± 0.12 tok/s | 10.43 ± 4.69s |
| 16k | 10 | 4453.92 ± 18.19 tok/s | 6.79 ± 1.62 tok/s | 45.76 ± 0.43 tok/s | 18.92 ± 9.43s |
| 25k | 1 | 3621.25 ± 18.50 tok/s | 22.75 ± 0.08 tok/s | 22.75 ± 0.08 tok/s | 6.39 ± 0.05s |
| 25k | 5 | 3561.78 ± 9.23 tok/s | 8.46 ± 2.36 tok/s | 27.93 ± 0.08 tok/s | 19.63 ± 8.87s |
| 25k | 10 | 3565.35 ± 8.21 tok/s | 5.40 ± 2.00 tok/s | 30.73 ± 0.12 tok/s | 35.67 ± 18.00s |
Run B : tenir 25k de contexte, monter la concurrency
Ensuite j’ai poussé le même contexte 25k plus fort. Plus de variation du contexte, juste ajouter des utilisateurs.
uvx llama-benchy \
--base-url http://localhost:8000/v1 \
--model gemma-4-26b-a4b-bf16 \
--pp 25000 \
--tg 256 \
--depth 0 \
--concurrency 5 10 20 \
--runs 3 \
--latency-mode generation \
--exit-on-first-fail \
--format mdPas d’OOM. Pas de crash. Le DGX Spark a survécu à 20 requêtes concurrentes à 25k de contexte.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 5 | 3559.17 ± 6.72 tok/s | 8.51 ± 2.40 tok/s | 27.88 ± 0.05 tok/s | 19.86 ± 9.00s |
| 10 | 3569.77 ± 2.99 tok/s | 5.37 ± 1.99 tok/s | 30.68 ± 0.09 tok/s | 35.44 ± 17.95s |
| 20 | 3563.64 ± 8.78 tok/s | 3.16 ± 1.41 tok/s | 32.26 ± 0.10 tok/s | 67.37 ± 36.44s |
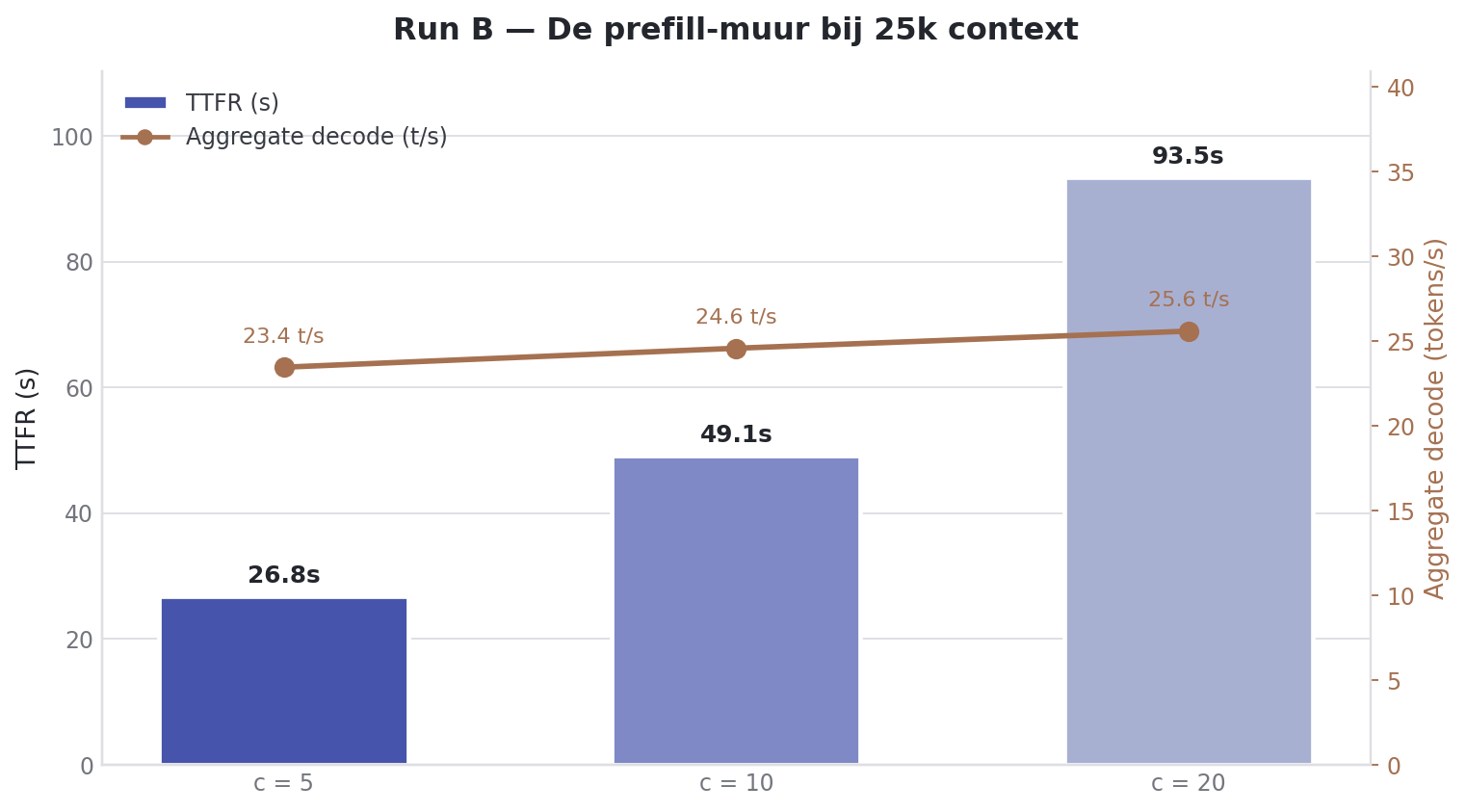
C’est le bord de stress du benchmark. Le decode agrégé reste autour de 30 tok/s, que tu mettes 5, 10 ou 20 utilisateurs. Par utilisateur il descend de 8.51 à 3.16 tok/s. Mais le vrai problème c’est le TTFT : à 20 utilisateurs la requête moyenne attend 67 secondes avant que le premier token n’arrive. Le serveur n’est pas cassé pour autant. Le workload ne colle juste plus à une attente de chat en temps réel.
Run C : prompt court, output long
Le Run C a inversé la forme. Pas 25k de contexte avec output court, mais 1024 prompt tokens et 1024 output tokens.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 1 | 4627.12 ± 374.91 tok/s | 23.86 ± 0.03 tok/s | 23.86 ± 0.03 tok/s | 0.31 ± 0.02s |
| 5 | 5701.55 ± 561.36 tok/s | 13.59 ± 1.05 tok/s | 54.67 ± 4.90 tok/s | 0.76 ± 0.11s |
| 10 | 6346.87 ± 64.52 tok/s | 10.92 ± 0.73 tok/s | 86.46 ± 1.74 tok/s | 1.26 ± 0.40s |
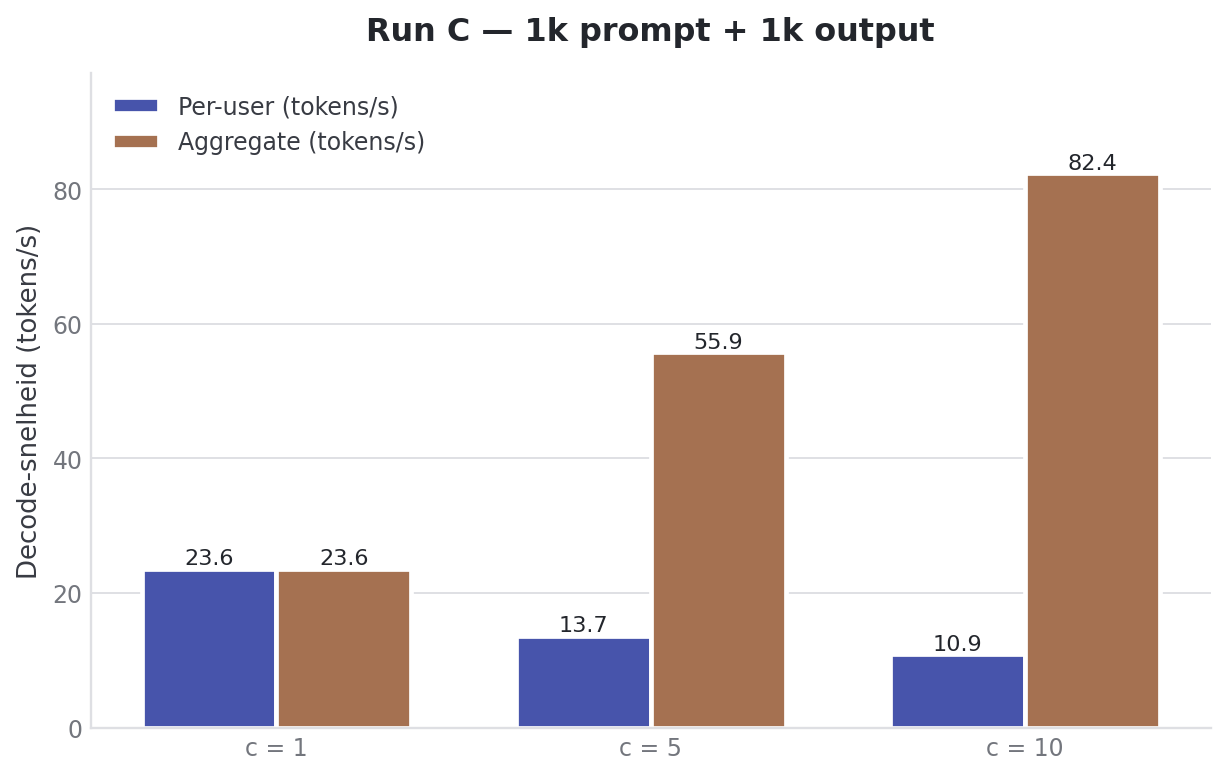
À dix utilisateurs en même temps, le TTFT reste à 1.3 seconde. Ça ressemble à du chat.
Run G : output encore plus long
Les Run A, B et C montraient assez pour rendre plausible l’histoire “le decode est stable, le prefill décide de l’attente”. Mais un scénario restait ouvert : et si l’output est encore beaucoup plus long ? Un agent qui génère du code. Un tool-call avec output structuré. Un long résumé.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 1 | 1993.94 ± 262.05 tok/s | 24.17 ± 0.02 tok/s | 24.17 ± 0.02 tok/s | 0.24 ± 0.01s |
| 5 | 3048.28 ± 496.15 tok/s | 14.32 ± 2.18 tok/s | 46.11 ± 11.57 tok/s | 0.38 ± 0.07s |
| 10 | 4800.80 ± 50.75 tok/s | 11.75 ± 0.68 tok/s | 83.77 ± 4.04 tok/s | 0.48 ± 0.01s |

Le decode/user sur 4096 tokens baisse à peine comparé aux 1024 tokens du C. À c=1 c’est 24.17 (G) vs 23.86 (C). À c=10 c’est 11.75 (G) vs 10.92 (C). Les longues générations ne se cumulent pas, elles durent juste proportionnellement plus longtemps. Et le TTFT est le plus bas ici : sous la demi-seconde à dix utilisateurs en même temps.
Run F : contexte moyen, plus d’utilisateurs
Entre le Run C (1k de contexte) et le Run B (25k de contexte) se trouvait un trou plus proche de la réalité. Un flow RAG typique avec quatre chunks de ~2k tokens arrive autour de 8k.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 5 | 5439.51 ± 32.60 tok/s | 12.11 ± 0.51 tok/s | 55.21 ± 1.49 tok/s | 4.32 ± 1.90s |
| 10 | 5466.71 ± 15.65 tok/s | 9.31 ± 0.77 tok/s | 78.36 ± 1.61 tok/s | 7.99 ± 4.02s |
| 20 | 5532.74 ± 5.39 tok/s | 6.05 ± 0.62 tok/s | 97.35 ± 3.50 tok/s | 14.61 ± 7.72s |
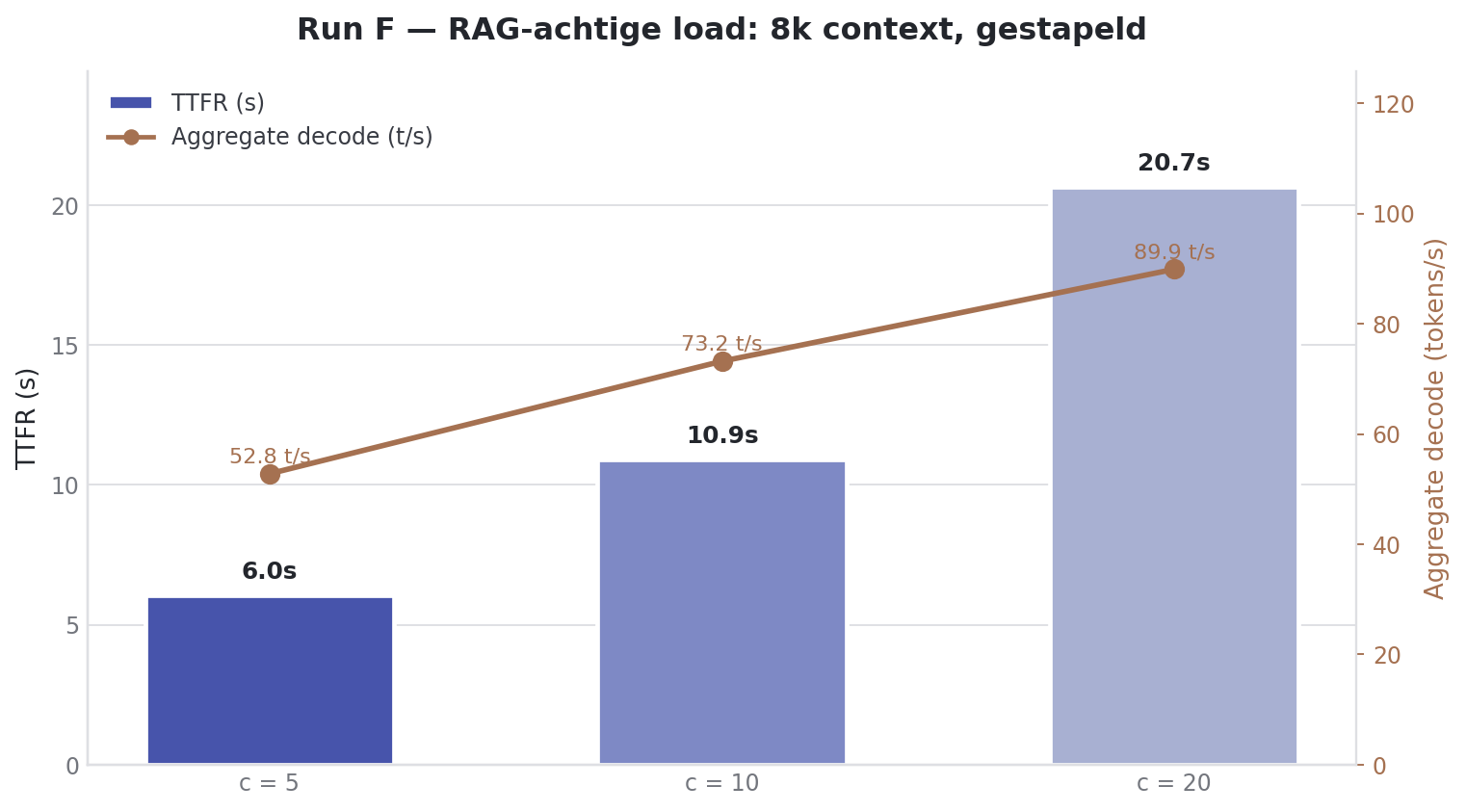
Trois observations.
Le prefill throughput reste à un plat 5.5k tok/s, que ce soit 5, 10 ou 20 utilisateurs. À 8k de contexte la machine est déjà saturée au niveau du prefill. Le decode agrégé continue de scaler : dans le Run B (25k) ça plafonnait à ~30 t/s, ici ça monte jusqu’à 97.4 t/s. Et le plus important : le TTFT à 8k de contexte est grosso modo un quart de ce qu’il est à 25k. Même concurrency, même machine, taille de prompt différente.
Run E : le multi-turn comme vrai travail de bureau
--depth 4 signifie : cinq tours d’affilée par requête (initial + quatre questions de suivi). Concurrency à 10 signifie : dix de ces conversations en parallèle.
| Users | Prefill total | Decode/user | Decode total | TTFT |
|---|---|---|---|---|
| 1 | 4716.21 ± 542.88 tok/s | 23.97 ± 0.10 tok/s | 23.97 ± 0.10 tok/s | 0.53 ± 0.06s |
| 5 | 5693.39 ± 128.08 tok/s | 13.07 ± 0.16 tok/s | 59.48 ± 2.26 tok/s | 1.32 ± 0.39s |
| 10 | 6096.81 ± 56.92 tok/s | 10.43 ± 0.35 tok/s | 92.42 ± 3.33 tok/s | 2.13 ± 0.83s |

Trois choses ont attiré l’attention, que je n’avais pas prévues au départ.
Le decode par utilisateur en multi-turn est identique au single-turn. Le multi-turn ne rend pas les tokens plus lents, seul le nombre de prefills augmente. Le decode agrégé à c=10 est de 92.42 t/s, le plus haut de n’importe quel run closed-loop. En multi-turn, vLLM reçoit un flux plus dense de requêtes dépendantes, et peut les batcher plus efficacement que dix prompts single-shot séparés. Et le TTFT à c=10 est en moyenne de 2.13 secondes sur les cinq tours. Sous trois secondes, ça ressemble encore à du chat.
Ce que les six runs closed-loop montrent ensemble
Un tableau qui met tout côte à côte à c=10 :
| Run | Prompt | Output | Depth | TTFT (c=10) | Decode/user (c=10) | Decode agrege (c=10) |
|---|---|---|---|---|---|---|
| G | 256 | 4096 | 0 | 0.48s | 11.75 t/s | 83.8 t/s |
| C | 1024 | 1024 | 0 | 1.26s | 10.92 t/s | 86.5 t/s |
| E | 2048 | 512 | 4 | 2.13s | 10.43 t/s | 92.4 t/s |
| F | 8192 | 512 | 0 | 7.99s | 9.31 t/s | 78.4 t/s |
| A | 16384 | 256 | 0 | 18.92s | 6.79 t/s | 45.8 t/s |
| A/B | 25000 | 256 | 0 | 35.67s | 5.40 t/s | 30.7 t/s |
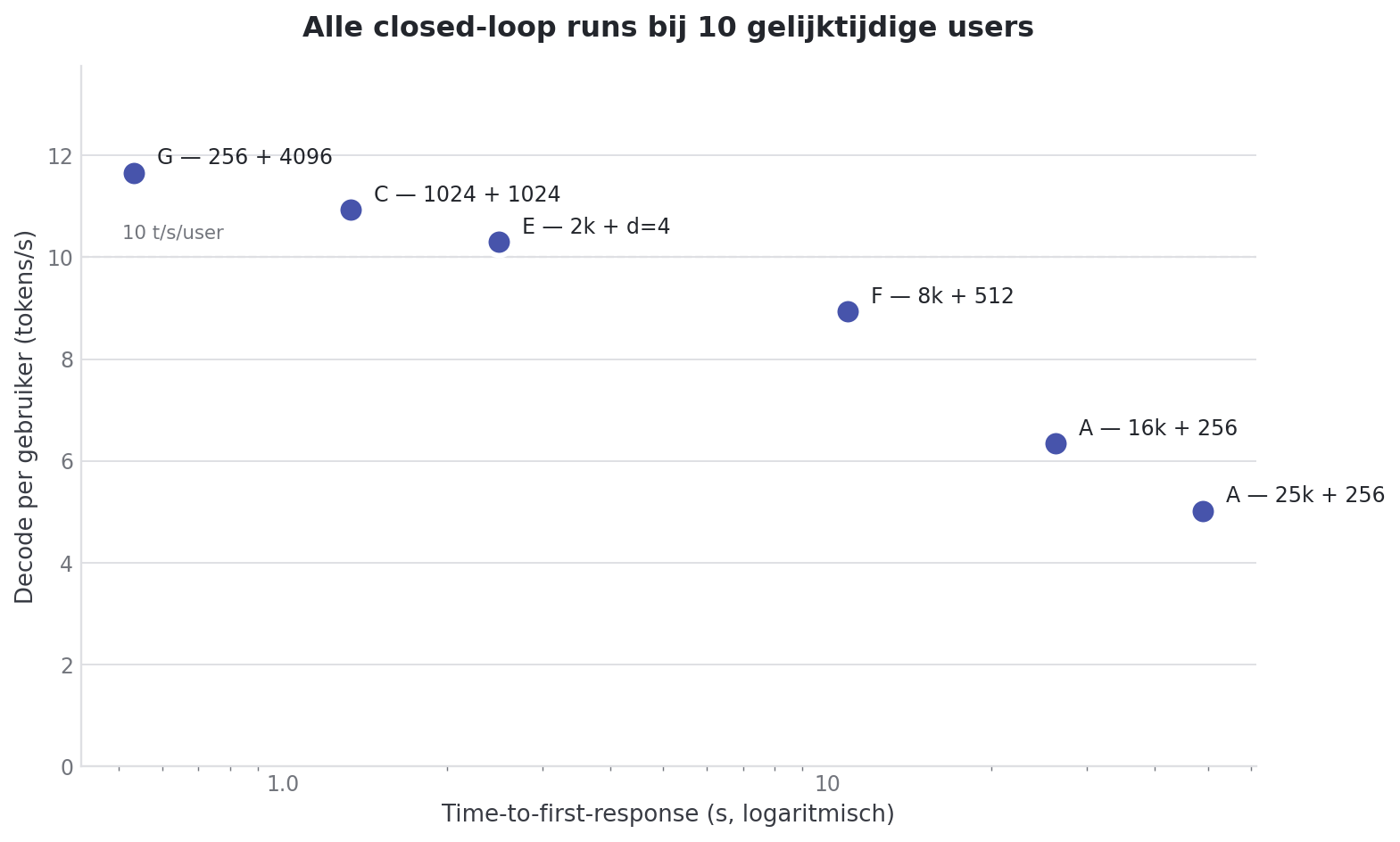
Deux motifs ressortent.
Le decode/user bouge à peine jusqu’à 8k de contexte. Entre le Run G et le Run F il y a un facteur 32 sur la taille du prompt et un facteur 8 sur la taille de l’output. Pourtant le decode/user y reste entre 9.3 et 11.8 tok/s. Ce n’est qu’à 16k+ que cette bande s’effondre.
Le TTFT bouge partout et est presque une fonction de la seule taille du prompt. Double le prompt et le TTFT double grosso modo avec. La taille de l’output et le depth ne comptent presque rien pour le TTFT.
C’est la conclusion closed-loop. Elle tient, et elle raconte une vraie partie de l’histoire. Mais il y a un trou dedans.
Mais ce sont des tests synthétiques
Les six runs ci-dessus testent la capacité. Des plafonds. Tous dans la même forme : N utilisateurs en lockstep, tous le même format de prompt, tous appuyant sur les boutons d’envoi en même temps. C’est une bonne façon de mesurer où ça casse. C’est une mauvaise façon de mesurer ce que ressent un vrai bureau.
Parce qu’un vrai bureau a 25 employés dont quelques-uns en moyenne font quelque chose en même temps. Un collègue pose une question courte. Un autre est en plein RAG avec 8k de contexte. Le troisième est au tour 4 d’une conversation. Et les requêtes n’arrivent pas en lockstep. Elles arrivent comme un processus de Poisson avec de temps en temps un burst, parce que quelqu’un vient de finir un mail et que trois collègues veulent un café en même temps.
C’est ce que vllm bench serve de vLLM sait faire et que llama-benchy ne sait pas :
- Open-loop avec arrival rate. Dispatcher les requêtes selon une distribution de Poisson ou de Gamma, au lieu du lockstep.
- Percentiles. P50, P90, P95, P99 sur TTFT, TPOT (time per output token), ITL (inter-token latency) et E2E. Fini les mean ± stddev.
- Datasets réalistes. Replay ShareGPT de 94k+ vraies conversations avec des longueurs de prompt qui varient naturellement et une structure multi-turn.
- Workloads mixtes. Échantillonner des prompts depuis une distribution au lieu de tester une seule forme fixe.
Trois tests ci-dessous, le même serveur (pas de redémarrage), mais avec ces autres lunettes sur le nez.
Test H : baseline de bureau réaliste
Le scénario : 25 personnes actives en moyenne, chacune envoie un prompt à peu près une fois toutes les 1-2 minutes, les prompts varient fortement en longueur. Les arrivées sont légèrement clumpy.
docker exec vllm-bench vllm bench serve \
--backend openai-chat \
--base-url http://localhost:8000 \
--endpoint /v1/chat/completions \
--model google/gemma-4-26B-A4B-it \
--tokenizer google/gemma-4-26B-A4B-it \
--served-model-name gemma-4-26b-a4b-bf16 \
--dataset-name random \
--random-input-len 4000 \
--random-output-len 500 \
--random-range-ratio 0.9 \
--num-prompts 200 \
--request-rate 0.3 \
--burstiness 0.7 \
--percentile-metrics ttft,tpot,itl,e2el \
--metric-percentiles 50,90,95,99 \
--seed 42Avec --random-range-ratio 0.9, les longueurs d’input varient de 399 à 7600 tokens, les outputs de 49 à 950. --burstiness 0.7 est un peu plus clumpy que du Poisson pur. Les gens appuient souvent sur entrée par petites rafales, pas comme un métronome. Target rate de 0.3 req/s = ~18 prompts/min sur 25 utilisateurs.
| Metric | Valeur |
|---|---|
| Successful requests | 200 / 200 |
| Achieved RPS | 0.27 (target 0.30) |
| Peak concurrent requests | 36 |
| Total token throughput | 1215 tok/s |
| Mean | P50 | P90 | P95 | P99 | |
|---|---|---|---|---|---|
| TTFT (ms) | 1395 | 1286 | 2284 | 2644 | 3316 |
| TPOT (ms) | 177 | 182 | 193 | 202 | 214 |
| E2E (ms) | 85921 | 85306 | 150192 | 162375 | 171351 |
L’utilisateur médian reçoit le premier token en 1.29s. Ça ressemble encore à du chat. Le tail reste dans les clous : le P99 attend 3.3 secondes, largement sous le double de la moyenne.
Et regarde le peak concurrent : 36. À un target rate de seulement 0.3 req/s. Aucun run closed-loop n’en approchait. La seule burstiness de Poisson, combinée à un temps de réponse moyen de ~86 secondes, produit des pics plus violents que n’importe quel stress-test du Run B. C’est la chose que le closed-loop ne peut littéralement pas montrer.
Test I : vraies conversations (replay ShareGPT)
Pattern d’arrivée identique au Test H, mais maintenant avec 250 vraies conversations multi-turn de ShareGPT V3 comme prompts. Certaines sont 1 tour de 200 tokens, d’autres sont 15 tours avec un contexte qui grandit à chaque fois.
docker exec vllm-bench vllm bench serve \
... \
--dataset-name sharegpt \
--dataset-path /tmp/ShareGPT_V3.json \
--num-prompts 250 \
--request-rate 0.3 \
--burstiness 0.7| Metric | Valeur |
|---|---|
| Successful requests | 250 / 250 |
| Achieved RPS | 0.30 (target 0.30) |
| Peak concurrent requests | 17 |
| Total token throughput | 133 tok/s |
| Mean | P50 | P90 | P95 | P99 | |
|---|---|---|---|---|---|
| TTFT (ms) | 376 | 353 | 469 | 509 | 637 |
| TPOT (ms) | 93 | 95 | 117 | 123 | 135 |
| E2E (ms) | 19600 | 10923 | 49525 | 63036 | 82596 |
C’est un autre univers que le Test H. TTFT P99 = 637 ms. 99% des utilisateurs voient le premier token en moins de 650 millisecondes. C’est vraiment une vitesse de chat.
Pattern d’arrivée identique au Test H, expérience totalement différente. La différence tient entièrement à la taille du prompt : les conversations ShareGPT font en moyenne 228 tokens, pas 4000. Prompt court = prefill bon marché = pas de pression de file = TTFT sous la seconde.
| Metric | Test H (random 4k) | Test I (ShareGPT) |
|---|---|---|
| Achieved RPS | 0.27 | 0.30 |
| Peak concurrent | 36 | 17 |
| TTFT P50 | 1286 ms | 353 ms |
| TTFT P99 | 3316 ms | 637 ms |
| TPOT P50 | 182 ms | 95 ms |
C’est aussi un avertissement : le workload synthétique du Test H exagère le poids d’un prompt de bureau moyen. Les conversations du monde réel sont plus légères que notre baseline random 4k, donc les chiffres de la pratique sont probablement plus proches du Test I que du Test H.
Test J : pic du lundi matin
Et si tout le monde arrive en même temps et se met à appuyer sur les boutons d’envoi ? Cinq fois la charge, max 25 requêtes concurrentes pour modéliser un vrai bureau.
docker exec vllm-bench vllm bench serve \
... \
--dataset-name random \
--random-input-len 4000 \
--random-output-len 500 \
--random-range-ratio 0.9 \
--num-prompts 300 \
--request-rate 1.5 \
--burstiness 1.0 \
--max-concurrency 25| Metric | Valeur |
|---|---|
| Successful requests | 300 / 300 |
| Configured RPS | 1.50 |
| Achieved RPS | 0.26 |
| Peak concurrent requests | 27 |
| Total token throughput | 1173 tok/s |
| Mean | P50 | P90 | P95 | P99 | |
|---|---|---|---|---|---|
| TTFT (ms) | 1370 | 1132 | 1932 | 2961 | 6157 |
| TPOT (ms) | 185 | 187 | 195 | 199 | 221 |
| E2E (ms) | 92752 | 91099 | 165179 | 172073 | 179139 |
C’est le chiffre clé : achieved rate 0.26 à un target de 1.5. Le système est throttle de presque 6x. Pas parce qu’il crashe (les 300 requêtes réussissent, aucun échec), mais parce que la file se remplit jusqu’à 25 et y retient les requêtes jusqu’à ce qu’il y ait de la place.
Compare le Test H (target 0.3) et le Test J (target 1.5) :
| Metric | Test H (0.3 rps) | Test J (1.5 rps) |
|---|---|---|
| Achieved RPS | 0.27 | 0.26 |
| TTFT P50 | 1286 ms | 1132 ms |
| TTFT P95 | 2644 ms | 2961 ms |
| TTFT P99 | 3316 ms | 6157 ms |
| TPOT P50 | 182 ms | 187 ms |
L’expérience médiane est même légèrement meilleure au Test J qu’au Test H (1.13s vs 1.29s). Le cap crée un flux plus régulier. Mais le tail est dramatiquement pire : le P99 double, de 3.3s à 6.2s.
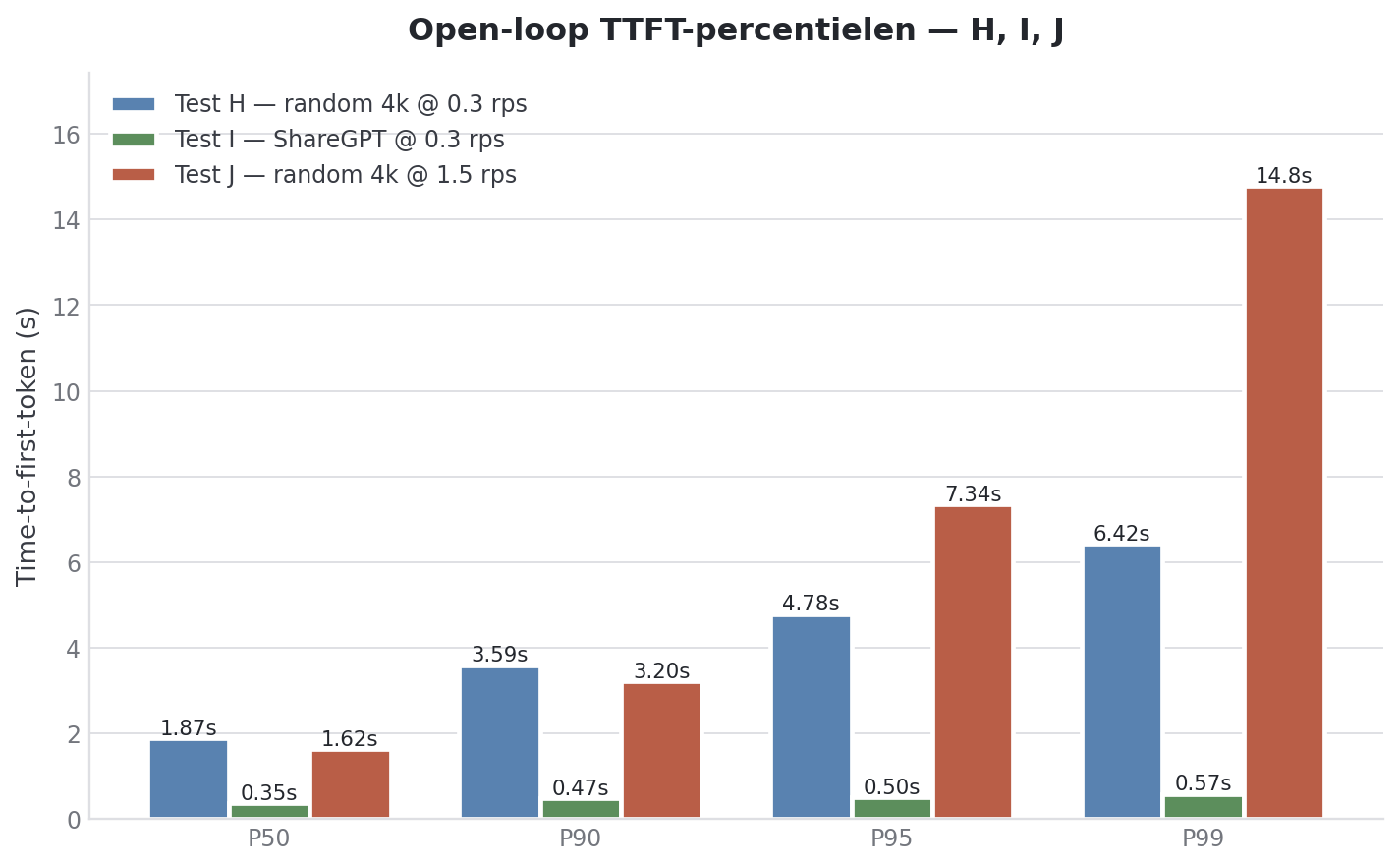
Le Spark ne scale pas sous oversubscribe, il met en file. C’est une bonne nouvelle : degradation gracieuse au lieu de crashes. Pour l’IA on-prem c’est vraiment le meilleur failure mode.
Ce que le closed-loop cache, ce que l’open-loop exagère
Les deux méthodes racontent chacune une partie différente de l’histoire. Toutes les deux vraies, toutes les deux incomplètes.
Le closed-loop sous-estime la profondeur de la file.
Dans le Run F j’ai testé c=10 comme “dix utilisateurs en même temps”. Ça sonne comme une situation de bureau raisonnablement chargée. Mais le Test H montre qu’un arrival rate organique de 0.3 req/s suffit déjà à produire des pics de 36 requêtes concurrentes. La revendication closed-loop “10 utilisateurs” est donc plus optimiste que ce que la pratique montre.
L’open-loop avec du synthétique exagère la charge réelle.
En même temps : le Test H utilise des prompts random 4k. Un vrai bureau ne pose pas 25 prompts moyens de 4k par minute. ShareGPT (Test I) est un bien meilleur proxy de “ce que les gens tapent”, en moyenne 228 tokens. Avec cette forme de workload, le peak concurrent est de 17 au lieu de 36, et le P99 TTFT de 637ms au lieu de 3.3s.
La pratique se situe donc entre le Run F et le Test I :
| Source | TTFT (P50 ou mean) | Peak concurrent |
|---|---|---|
| Run F (closed-loop, 10 users, 8k) | 7.99 s | 10 |
| Test H (open-loop, 0.3 rps, 4k random) | 1.29 s P50 / 3.3s P99 | 36 |
| Test I (open-loop, 0.3 rps, ShareGPT) | 0.35 s P50 / 0.64s P99 | 17 |
| Test J (open-loop, 1.5 rps, 4k random, cap 25) | 1.13 s P50 / 6.2s P99 | 27 |
Pour un bureau avec des prompts réalistes et un pattern d’arrivée réaliste, le Test I est le plus proche de ce que ressentent les gens. Pour la planification de capacité (“et si tout le monde pose une question RAG de 8k en même temps ?”), le Run F est le plus proche de ce que la machine peut digérer.
Le tail raconte ce que la moyenne cache
llama-benchy donnait seulement mean ± stddev. Ça a l’air de beaucoup d’information, mais ça cache la partie qui compte le plus pour tes utilisateurs : le tail.
Le mean TTFT du Test I est de 376ms. Ça a l’air bien. Mais qu’est-ce que ça dit du 1% d’utilisateurs où la file a justement grimpé ? Rien. Pour ça il te faut le P99, et il est à 637ms. Dans ce cas pas de problème (les deux sous la seconde), mais c’est le principe que tu dois connaître.
Le mean TTFT du Test H est de 1395ms. Le P99 est de 3316ms. Largement plus de deux fois pire que la moyenne pour le 1% malchanceux.
Le mean TTFT du Test J est de 1370ms. Le P99 est de 6157ms. Largement quatre fois la moyenne.
Pour les décisions de SLA (“notre système répond en moins de 3 secondes à 95% des requêtes”) tu as besoin de ces percentiles. Mean ± stddev peut suggérer un SLA que tu ne tiens pas aux moments qui comptent le plus, c’est-à-dire quand c’est chargé.
C’est pourquoi le blog ne peut pas se reposer uniquement sur llama-benchy. Tester la capacité est une chose. Rapporter la tail latency en est une autre.
Le decode n’est pas le problème
Avec un seul utilisateur, le decode reste presque plat.
4k de contexte atteint 24.08 tok/s par utilisateur. 25k de contexte atteint 22.75 tok/s. 4096 output tokens (Run G, c=1) atteint 24.17 tok/s. Multi-turn avec depth 4 (Run E, c=1) atteint 23.97 tok/s. Quatre workloads différents, tous à moins de 6 pourcent les uns des autres.
À dix utilisateurs en même temps il se passe quelque chose de comparable, juste sur une ligne plus basse. Run G : 11.75 tok/s/user. Run C : 10.92. Run E : 10.43. Run F : 9.31. Et dans les tests open-loop : le Test I donne TPOT P50 = 95ms = ~10.5 tok/s/user. Les Test H et J donnent TPOT P50 = ~185ms = ~5.4 tok/s/user (parce que les pics y atteignent 25+ concurrent).
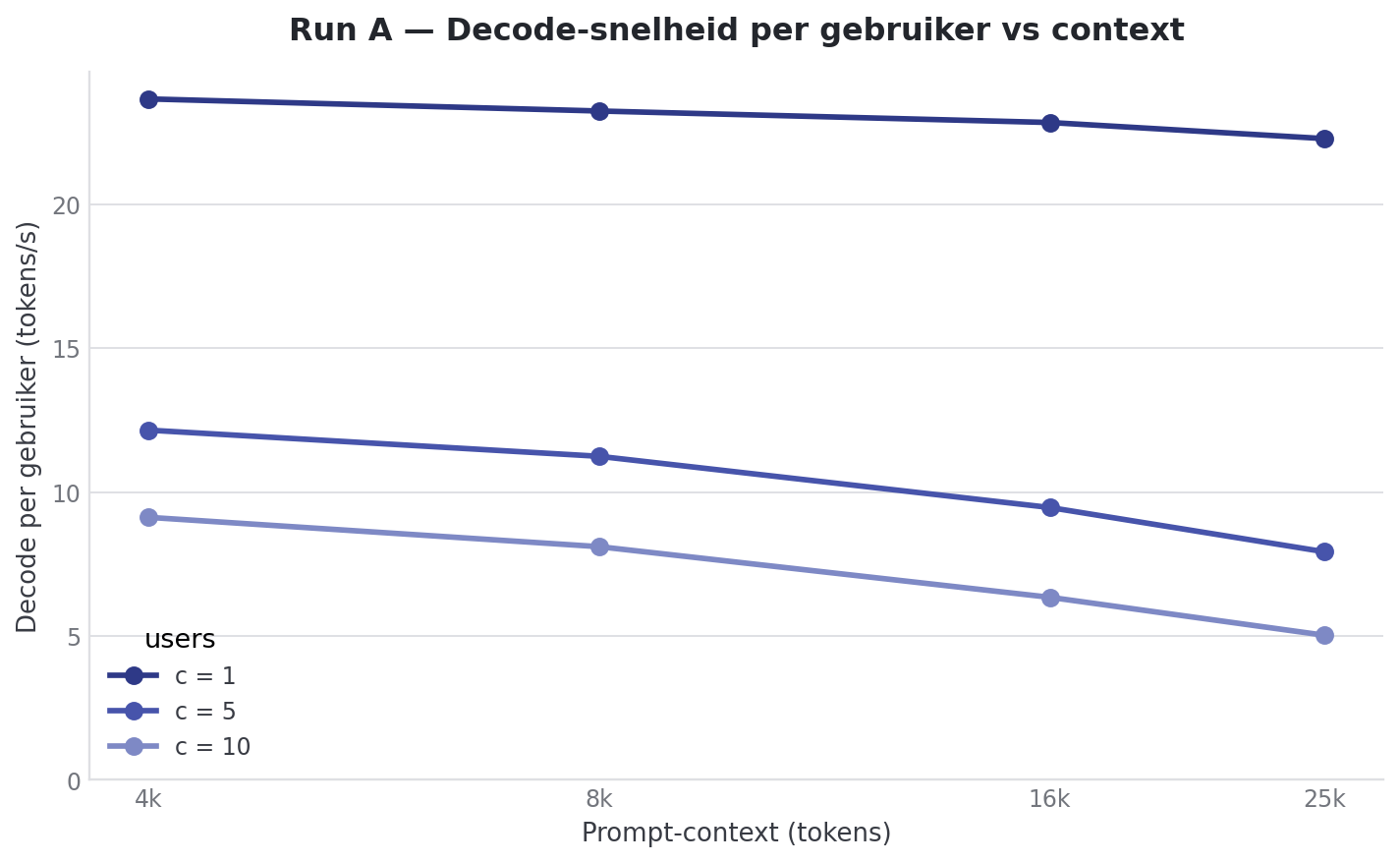
Bref : la vitesse de decode par token est une fonction de la charge concurrente moyenne, pas de la longueur du prompt, de la longueur de l’output, du multi-turn ou du pattern d’arrivée. Ce n’est qu’à 16k+ de contexte combiné à plusieurs utilisateurs (Run A) qu’elle descend vraiment sous 7 t/s/user.
La concurrency en soi n’est pas le problème. Le long output non plus. Le multi-turn non plus. Seul un grand contexte en même temps que plusieurs utilisateurs mange le decode.
Le prefill est le mur
Ce que tu sens en premier, c’est attendre.
Avec un seul utilisateur à 25k de contexte, il faut un bon 6 secondes avant que la première réponse arrive. À cinq utilisateurs ça devient 19.9 secondes. À dix ça devient 35.4 secondes. À vingt ça devient 67.4 secondes.
Le Run F montre que c’est linéaire à la fois en concurrency et en contexte. 8k de contexte à 20 utilisateurs donne 14.6 secondes, environ un quart des 67.4 secondes à 25k de contexte, pour la même concurrency. Coupe le prompt en deux, coupe l’attente en deux.
Et le Test J montre : dès que tu pousses le système au-delà de son plafond de débit, toute cette attente supplémentaire passe dans le tail. Le TTFT médian reste stable autour de 1.1-1.3s, mais le P99 file à 6 secondes. La douleur de la surcharge tombe sur un petit groupe, pas sur tout le monde.
C’est là que se trouve la vraie limite.
Pas : le DGX Spark peut-il générer des tokens ? Oui.
Pas : le KV-cache peut-il encaisser 20 × 25k ? Oui aussi.
Pas : s’arrête-t-il sous surcharge ? Non, il met gentiment en file.
Mais : ça ressemble-t-il encore à du chat ? Pas pour 25k. Pour 8k c’est déjà la zone grise. Pour 2k avec multi-turn tout simplement bien. Pour des prompts réalistes façon ShareGPT avec 25 utilisateurs répartis de façon organique : un oui limpide.
Où ça convient
Ces benchmarks rendent le choix on-prem plus concret.
Oui pour un environnement de bureau où 10 à 25 personnes utilisent de l’IA locale répartie sur la journée. Le Test I est la preuve : 250 vraies conversations ShareGPT, arrival rate de 0.3 req/s, P99 TTFT de 637ms. L’utilisateur médian voit le premier token en 353 millisecondes. C’est exactement le scénario de bureau, et voilà ce que ça donne au ressenti.
Oui pour des flows RAG avec contexte moyen. Le Run F a donné les chiffres au départ : prompt 8k, 10 users, TTFT 8s, streaming 9.3 tok/s. Le Test H confirme que la variante open-loop reste utilisable : P99 TTFT 3.3s. Pas du temps réel, mais dans des limites attendables.
Oui pour les agents et la génération de code. Le Run G est la confirmation : instruction courte, 4k+ tokens d’output, dix tâches parallèles. TTFT sous la demi-seconde, 11.75 tok/s/user.
Oui pour les conversations multi-turn. Le Run E donne 2.1s de TTFT à 10 conversations parallèles de 5 tours. Decode identique au single-turn.
Prudence avec 5+ utilisateurs à 25k de contexte en même temps. 19.9 secondes de TTFT ce n’est plus du chat, mais c’est utilisable pour des analyses.
Prudence avec les revendications de SLA basées sur des moyennes. Le mean TTFT de 1.4s du Test H pourrait sonner acceptable, mais le P99 est à 3.3s. Des décisions basées sur les percentiles, pas sur la moyenne.
Non pour un support-chat où dix à vingt utilisateurs envoient 25k de contexte par session en même temps et attendent tous une réponse en temps réel. Ou : un support-chat sous une charge façon Test J (1.5 rps de prompts 4k). Ça peut techniquement tourner (aucun échec), mais un P99 TTFT de 6 secondes est un cas limite pour du chat.
Ce que ces tests ne disent pas
Ce n’est pas une comparaison MoE-vs-dense. Je veux tester ça à part, et alors pas seulement avec du throughput. Si tu compares MoE et dense, tu dois aussi tester des prompts : résumer, questions de code, choix d’outil, classification de tickets, un long morceau de contexte avec étapes de suivi. Sinon tu mesures seulement à quel point le moteur tourne fort, pas s’il roule dans la bonne direction.
Ce n’est pas non plus un test avec le prefix caching activé. C’est volontaire. Je voulais voir le coût brut du prefill, pas un benchmark qui s’embellit parce que les prompts se ressemblent. Un prochain article l’ajoutera : ces mêmes runs de contexte 8k et 25k et les tests open-loop avec --enable-prefix-caching. Mon intuition : les Test H et J en profitent modestement (données random, peu de recouvrement), le Test I en profite sérieusement (les vraies conversations ont des system prompts et du contexte qui se recouvrent), et le Run F va sensiblement plus vite. Mais il faut le mesurer.
Là où j’atterris
Mon attente au départ était que le DGX Spark avec ce modèle MoE se remplirait plus tôt sur de grands context windows. C’est arrivé, mais autrement que je pensais.
La mémoire n’était pas le show-stopper. Le Run B a tenu 20 utilisateurs à 25k de contexte sans OOM. Le Test J a survécu à 1.5 req/s sans une seule requête échouée. La limite pratique était toujours dans la prefill-latency, pas dans la capacité.
Et après neuf tests il s’avère : c’est en fait la seule limite que tu sens.
Le decode/user est presque une constante pour cette machine. Entre 9 et 12 tokens par seconde à dix utilisateurs concurrents, dans six workloads closed-loop différents. En open-loop avec des prompts ShareGPT réalistes : 10.5 t/s/user. Ce n’est qu’à 16k de contexte ou à des pics synthétiques de 25+ concurrent que ça descend sous 7 t/s.
Ce qui varie, c’est combien de temps quelqu’un attend avant que le texte commence. À 256 prompt tokens c’est une demi-seconde, même avec dix utilisateurs. À 2048 prompt tokens avec cinq tours en moyenne 2.1 secondes. À 8192 prompt tokens avec dix utilisateurs huit secondes. À 25k avec dix utilisateurs 35 secondes. Sous une charge ShareGPT réaliste de 0.3 rps : 353 millisecondes pour la médiane, 637 millisecondes pour le 1% malchanceux.
Et dès que tu pousses le système au-delà de sa capacité, il ne scale pas, il met en file. Le Test J a montré qu’un target de 1.5 req/s se fait throttle à 0.26 achieved, avec la douleur entièrement dans le tail (P99 6.2s) tandis que la médiane reste stable. Pour l’IA on-prem c’est le meilleur failure mode que tu puisses espérer : personne ne crashe, certains attendent plus longtemps.
Ce n’est pas un “cette machine y arrive ou pas”. C’est “choisis le workload qui correspond à ce que l’utilisateur attend, et accepte que 1% des requêtes ait une attente désagréable aux moments de pic”.
Pour un à trois utilisateurs avec un grand contexte il est utilisable. Pour dix utilisateurs avec un contexte moyen il est très bien. Pour dix utilisateurs avec des conversations multi-turn il est en fait à son meilleur. Pour un bureau de 25 personnes avec des prompts réalistes et un pattern d’arrivée organique il est étonnamment bon : TTFT sous la seconde pour 99% des requêtes, mesuré sur de vraies données de conversation.
Pour des agent-flows avec de longs outputs il est solide. Pour vingt prompts 25k concurrents ou pour 1.5 rps d’oversubscribe ce n’est plus du chat en temps réel. Là tu dois mettre en file, activer le prefix caching, ou router ce type de travail autrement.
Deux méthodes mesurent deux choses. Les benchmarks closed-loop montrent ce que la machine peut faire. Le replay open-loop montre ce que l’utilisateur ressent. Le DGX Spark est une machine d’IA locale solide pour le travail de bureau, tant que tu sais quel bouton décide de ce que tu ressens.
Le decode vend le benchmark. Le prefill décide de l’expérience. Et dès que tu dépasses la limite, le Spark met en file au lieu de casser, et c’est le troisième chiffre qu’un choix on-prem doit pouvoir lire.